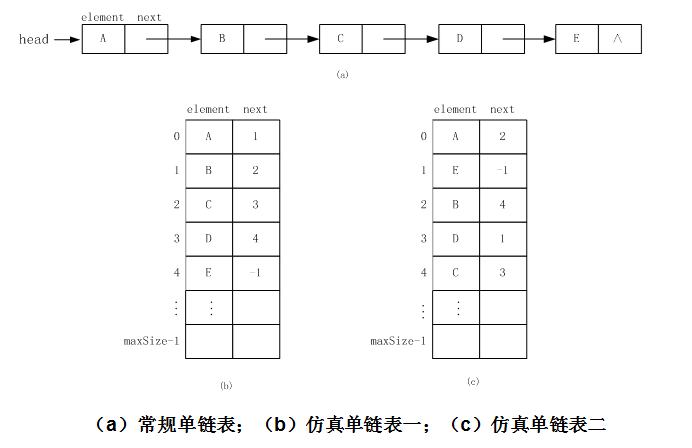
一、单向循环链表:
1、概念:
单向循环链表是单链表的另一种形式,其结构特点是链表中最后一个结点的指针不再是结束标记,而是指向整个链表的第一个结点,从而使单链表形成一个环。
和单链表相比,循环单链表的长处是从链尾到链头比较方便。当要处理的数据元素序列具有环型结构特点时,适合于采用循环单链表。
和单链表相同,循环单链表也有带头结点结构和不带头结点结构两种,带头结点的循环单链表实现插入和删除操作时,算法实现较为方便。
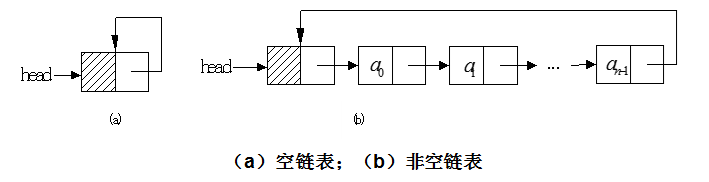
带头结点的循环单链表的操作实现方法和带头结点的单链表的操作实现方法类同,差别仅在于:
(1)在构造函数中,要加一条head.next = head 语句,把初始时的带头结点的循环单链表设计成上图中(a)所示的状态。
(2)在index(i)成员函数中,把循环结束判断条件current != null改为current != head。
2、单链表的代码实现:
1、结点类Node的实现代码
public class Node {
public Object data;//保存当前结点的数据
public Node next;//指向下一个结点
public Node(Object data){
this.data = data;
}
}
2、循环链表类CircleList的实现代码
public class CircleList {
private Node head;
public CircleList(){
head = new Node(0);
head.next = null;
}
//在指定位置插入结点
public boolean insert(Object data,int pos){
boolean ret = (head != null) && (data != null) && (pos >= 0);
if(ret){
Node node = new Node(data);
if(head.next == null){
//插入的结点前,循环链表中没有结点。
head.next = node;
node.next = node;
}else{
if(pos >= (Integer)head.data){
pos = (Integer)head.data;
}
Node currentNode = head.next;
//若currentNode.next == head.next,就说明currentNode是最后一个结点
for(int i = 0;(i < pos) && (currentNode.next != head.next);i++){
currentNode = currentNode.next;
}
node.next = currentNode.next;
currentNode.next = node;
//插入位置的下标为0时
if(pos == 0){
head.next = node;
}
}
head.data = (Integer)head.data + 1;
}
return ret;
}
//获取链表中下标为pos的结点
public Object get(int pos){
Object ret = null;
if(head != null && pos >= 0 && pos < (Integer)head.data){
Node node = head;//头结点
//找到要删除的结点
for(int i = 0;i<=pos;i++){
node = node.next;
}
if(node != null){
ret = node.data;
}
}
return ret;
}
//删除链表中下标为pos的结点
public Object delete(int pos){
Object ret = null;
if(head != null && pos >= 0 && pos < (Integer)head.data){
Node node = head;//头结点
Node currentNode = null;//要删除的结点
//找到要删除结点的前一个结点
for(int i = 0;i<pos;i++){
node = node.next;
}
currentNode = node.next;
//获取要删除结点的数据
if(currentNode != null){
ret = currentNode.data;
}
//要删除的结点是循环链表中的第一个结点
if(head.next == currentNode){
head.next = currentNode.next;
}
//删除结点
node.next = currentNode.next;
head.data = (Integer)head.data - 1;
}
return ret;
}
//清空链表
public void clear(){
if(head != null){
head.data = 0;
head.next = null;
}
}
//注销链表
public void destroy(){
if(head != null){
head = null;
}
}
//获取链表中结点的个数
public int length(){
int ret = -1;
if(head != null){
ret = (Integer)head.data;
}
return ret;
}
//打印循环链表中的数据
public void display(){
if(head != null){
Node node = head;
for(int i = 0;i < (Integer)head.data;i++){
node = node.next;
System.out.print(node.data+" ");
}
}
}
}
3、测试类Test的代码
public class Test {
public static void main(String[] args) {
CircleList list = new CircleList();
list.insert("结点1", 0);
list.insert("结点2", 1);
list.insert("结点3", 2);
list.insert("结点4", 3);
list.insert("结点5", 4);
list.insert("结点6", 5);
System.out.println("链表中的元素为:");
list.display();
System.out.println("\n链表中结点的个数:"+list.length());
System.out.println("\n获取链表中下标为2的结点:"+list.get(2));
System.out.println("删除链表中下标为0的结点:"+list.delete(0));
System.out.println("链表中的元素为:");
list.display();
System.out.println("\n链表中结点的个数:"+list.length());
list.clear();
list.destroy();
}
}
4、程序运行结果
链表中的元素为: 结点1 结点2 结点3 结点4 结点5 结点6 链表中结点的个数:6 获取链表中下标为2的结点:结点3 删除链表中下标为0的结点:结点1 链表中的元素为: 结点2 结点3 结点4 结点5 结点6 链表中结点的个数:5
二、双向循环链表:
双向链表:
双向链表是每个结点除后继指针外还有一个前驱指针。和单链表类同,双向链表也有带头结点结构和不带头结点结构两种,带头结点的双向链表更为常用;另外,双向链表也可以有循环和非循环两种结构,循环结构的双向链表更为常用。
双向循环链表:
在双向链表中,每个结点包括三个域,分别是element域、next域和prior域,其中element域为数据元素域,next域为指向后继结点的对象引用,prior域为指向前驱结点的对象引用。下图为双向链表结点的图示结构:

如下图是带头结点的双向循环链表的图示结构。双向循环链表的next和prior各自构成自己的单向循环链表:
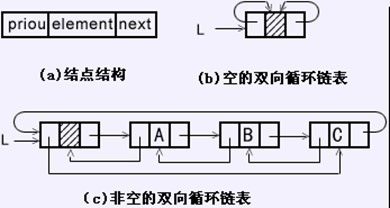
在双向链表中,有如下关系:设对象引用p表示双向链表中的第i个结点,则p.next表示第i+1个结点,p.next.prior仍表示第i个结点,即p.next.prior == p;同样地,p.prior表示第i-1个结点,p.prior.next仍表示第i个结点,即p.prior.next == p。下图是双向链表上述关系的图示:

双向循环链表的插入过程:
下图中的指针p表示要插入结点的位置,s表示要插入的结点,①、②、③、④表示实现插入过程的步骤:
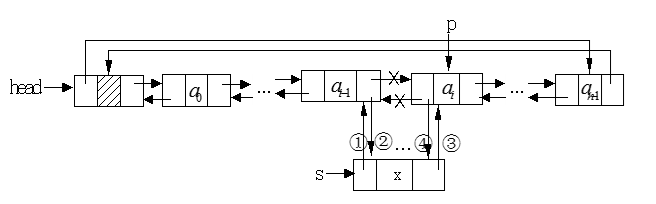
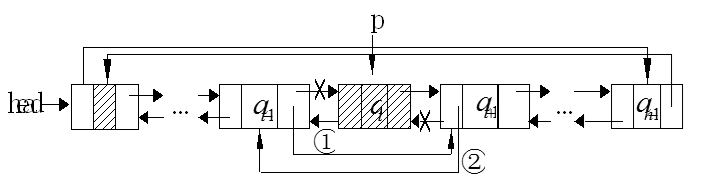
循环双向链表的删除过程:
下图中的指针p表示要插入结点的位置,①、②表示实现删除过程的步骤:
2、双向循环链表的代码实现
public class DbLinkedList<T>
{
//定义内部类,用作链表的节点
private class Node<T>
{
Node<T> pre; //指向前一个节点
Node<T> next; //指向后一个节点
T value; //当前节点的值
public Node(T value, Node<T> next, Node<T> pre)
{
this.value = value;
this.next = next;
this.pre = pre;
}
public String toString()
{
return this.value + "";
}
}
private Node<T> header; //定义头节点
private int size; //定义链表的长度
public DbLinkedList()
{
header = new Node<T>(null, null, null);//空的头节点,用来区分双向循环链表的首尾
header.pre = header.next = header; //双向循环链表,首尾相连
size = 0;
}
public DbLinkedList(Collection<? extends T> collection)
{
this();
addAll(this.size, collection);
}
public boolean add(T value)//在链表的尾巴上面加一个节点, 相当于在header节点前面加一个节点
{
return add(header, value);
}
public boolean add(int index, T value)//指定index处加入节点
{
return add(entry(index), value);
}
public boolean remove(Object obj)//删除指定value的节点
{
Node<T> node;
//1. 从header.next往后遍历,再到header时结束
for(node = header.next; node!=header; node=node.next)
{
if(node.value == obj || (obj!=null && obj.equals(node.value)))
{
remove(node);
return true;
}
}
//2.java.util.LinkedList实现,先区分null再遍历,个人感觉效率差不多呀,希望有人赐教
/*
if(obj==null)
{
for(node = header.next; node!=header; node=node.next)
{
if(node.value == null)
{
remove(node);
return true;
}
}
}
else
{
for(node = header.next; node!=header; node=node.next)
{
if(node.value == obj || obj.equals(node.value))
{
remove(node);
return true;
}
}
}
*/
return false;
}
public T remove(int index)//删除指定index节点
{
return remove(entry(index));
}
public boolean addAll(Collection<? extends T> collection)
{
return addAll(this.size, collection);
}
//在指定index位置添加collection里的所有元素
public boolean addAll(int index, Collection<? extends T> collection)
{
if(collection==null || collection.size()==0)
{
return false;
}
//获取指定位置节点,如果index==size,则在末尾添加节点,即header节点之前
//当index==size时,调用entry方法会抛异常,所以三则表达式很有必要
Node<T> node = index == this.size ? this.header : entry(index);
Object[] objArray = collection.toArray();
int len = objArray.length;
Node<T> preNode = node.pre;
for(int i=0; i<len; i++)
{
//新建一个节点,新节点的next指向node,新节点的pre指向node的pre
//完成指向过程node.pre←newNode→node
//当第二次迭代时,preNode=newNode1(i=1创建的newNode), newNode1←newNode2(i=2创建的newNode)→node
Node<T> newNode = new Node<T>((T) objArray[i], node, preNode);
//维持双向链表的指向,将node的pre节点的next指向新节点,完成指向过程node.pre→newNode
//当第二次迭代时,newNode1→newNode2
preNode.next = newNode;
//将preNode指向newNode,当第二次迭代时,preNode往后移动一位
preNode = newNode;
}
//迭代完成后,node的前一个节点指向preNode(即最后一次创建的newNode),preNode←node
//如果len=2,完成的链就变成这样preNode→←newNode1→←newNode2→←node
node.pre = preNode;
//长度加len
this.size += len;
return true;
}
private T remove(Node<T> node)
{
//node的前一个节点next指向node的下一个节点
//node的下一个节点pre指向node的前一个节点
//A→node←B改成A→←B
node.pre.next = node.next;
node.next.pre = node.pre;
//node的前后指向null
//A←node→B改成null←node→null
node.pre = node.next = null;
T value = node.value;
node.value = null;
this.size--;
return value;
}
public T get(int index)
{
return entry(index).value;
}
private Node<T> entry(int index) //迭代至index处的节点
{
rangeIndex(index); //判断index是否越界
Node<T> node = this.header;
//判断index是否小于size的一半,如果小于就从header往后开始迭代,否则就从header往前开始迭代,提高效率
//例如有一个链表header→A→B→C→D→header
if(index < (this.size>>1))
{
//因为header是空的头节点,所以i要小于等于index
//例如index=1, 小于size的一半2
//i=0时,node=A
//i=1时,node=B,然后跳出循环
for(int i=0; i<=index; i++)
{
node = node.next;
}
}
else
{
//例如index=2,不小size的一半
//i=3, node等于header的前一个, node=D
//i=2, node=C,然后跳出循环
for(int i=this.size-1; i>=index; i--)
{
node = node.pre;
}
}
return node;
}
private void rangeIndex(int index)
{
if(index < 0 || index >= this.size)
{
throw new IndexOutOfBoundsException("index错误");
}
}
private boolean add(Node<T> node, T value)
{
//新建一个节点,新节点的next指向node,新节点的pre指向node的pre
//完成指向过程node.pre←newNode→node
Node<T> newNode = new Node<T>(value, node, node.pre);
//维持双向链表的指向,将node的pre节点的next指向新节点,完成指向过程node.pre→newNode
node.pre.next = newNode;
//node节点的前一个节点指向新节点,完成指向过程newNode←node
node.pre = newNode;
//上面两行代码不能颠倒,否则node的前一个节点会被覆盖成新节点,会丢失node原来的前一个节点的next指向
//上述代码完成了在node节点和node前一个节点之间加入一个新节点,并维护了双向关系
this.size++;
return true;
}
public void clear()
{
Node<T> node = header.next;
//将每一个节点的双向指向都清空,这样每个节点都没有被引用,可以方便垃圾回收器回收内存
while(node != header)
{
//将node的下一个节点临时保存起来
Node<T> tempNode = node.next;
//将node的下一个节点和上一个节点置空
node.next = node.pre = null;
//将node的值也置空
node.value = null;
//将node移动到下一个节点
node = tempNode;
}
//清空header的双向指向null
this.header.next = this.header.pre = this.header;
this.size = 0;
}
public boolean isEmpty()
{
return this.size == 0;
}
public int size()
{
return this.size;
}
}
三、仿真链表:
在链式存储结构中,我们实现数据元素之间的次序关系依靠指针。我们也可以用数组来构造仿真链表。方法是在数组中增加一个(或两个)int类型的变量域,这些变量用来表示后一个(或前一个)数据元素在数组中的下标。我们把这些int类型变量构造的指针称为仿真指针。这样,就可以用仿真指针构造仿真的单链表(或仿真的双向链表)。